Thinking with Comics: Enhancing Multimodal Reasoning through Structured Visual Storytelling
Harbin Institute of Technology

We propose "Thinking with Comics" — a novel reasoning paradigm that uses sequential comic panels as an intermediate reasoning medium, bridging the gap between static images and videos while preserving temporal logic, embedded text, and visual storytelling for enhanced VLM reasoning.

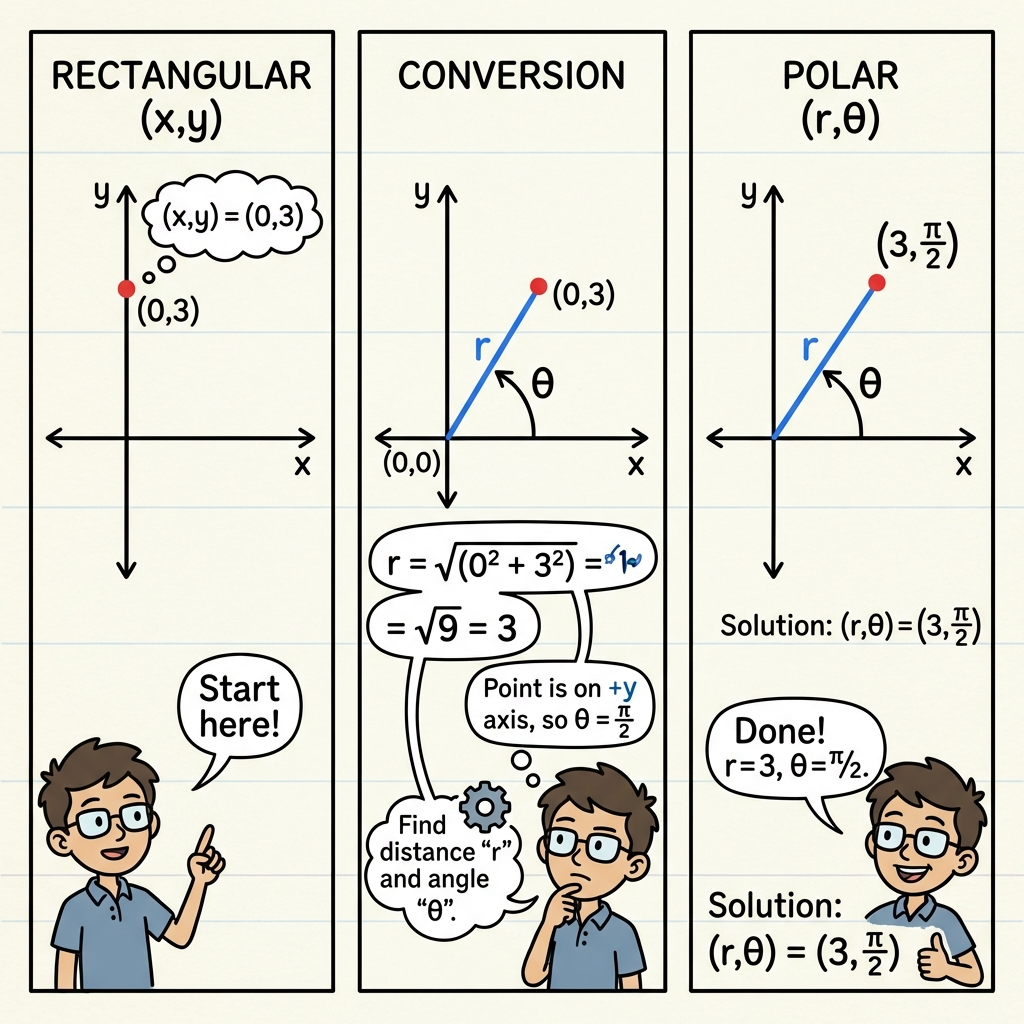
Math problem solved through visual storytelling

Silice-of-life style

Multi-step arithmetic reasoning visualized

Slice-of-life Style

Role-playing Style

Cartoon Style
Chain-of-Thought (CoT) has significantly improved the reasoning abilities of large language models, making "thinking with text" a core reasoning paradigm. Recent advances have extended this to "thinking with images" and "thinking with video," but each modality still has clear limitations.
To address these limitations, we introduce "Thinking with Comics" — a distinctive narrative form that retains temporal logic, embedded text, dynamic reasoning, and imagination like video, yet with higher information density and lower computational cost than video-based reasoning.
Our experiments demonstrate that comics serve as an effective reasoning medium that outperforms image-based reasoning on multi-step temporal tasks while requiring significantly lower cost than video-based approaches.
Detective-style comics provide clearer causal structure for logical reasoning tasks, achieving +28.5% improvement over documentary style.
With only 13.4% of the computational cost, comics were able to surpass the accuracy of video reasoning.
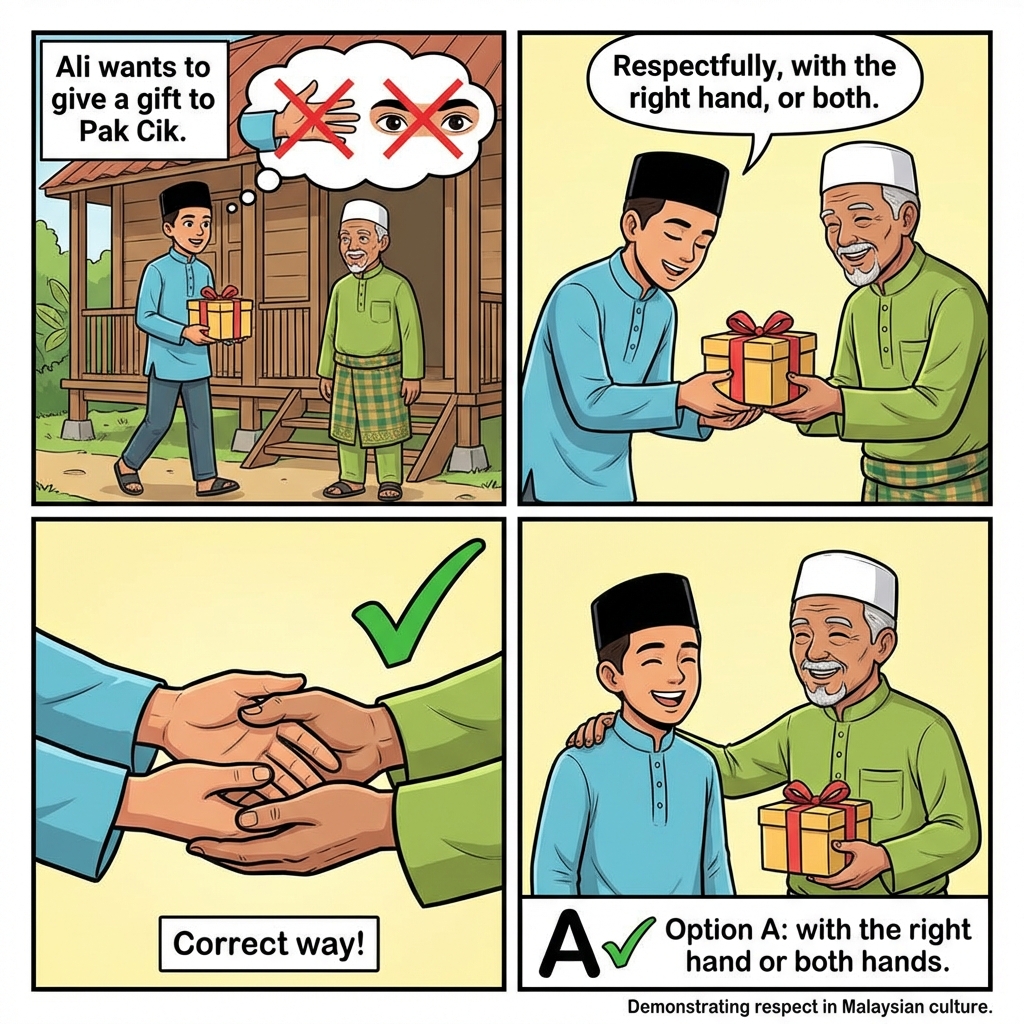
Embedded text in comics provides semantic anchoring, improving accuracy by +18.1% on cultural understanding tasks.
Models actively use the logic between panels (gutters), with 2.4% accuracy drop when panels are shuffled.
"Thinking with Comics" can be instantiated through two paths:
Comic generation is the reasoning process. The answer is extracted from the final panel.
Comic serves as explicit intermediate reasoning representation, processed by a VLM for joint reasoning.
Different comic styles act as "Visual System Prompts" for different task types:
Best for logical reasoning
+32% on GSM8KEducational presentation
BaselineRelatable scenarios
+19.1% avg* denotes results from Tong et al. (2025); ★ indicates evaluation on 50 sampled instances.
| Category | Model / Method | Notes | MATH-500 | GSM8K | MathVista | DocVQA | CulturalBench (E/H) |
|---|---|---|---|---|---|---|---|
| MLLM | GPT-5.2 | direct | 99.0 | 100.0 | 67.5 | 72.8 | 88.3 / 84.4 |
| Gemini-3-Pro | direct | 100.0 | 99.0 | 71.5 | 94.5 | 90.4 / 90.0 | |
| Claude-Sonnet 4.5 | direct | 99.0 | 100.0 | 72.5 | 92.6 | 87.2 / 76.5 | |
| Reasoning LLM | DeepSeek-R1 | CoT | 90.4 | 96.1 | — | — | 87.2 / 85.1 |
| Qwen3-235B-A22B | CoT | 92.4 | 94.3 | — | — | 83.1 / 82.5 | |
| Think with Image | TWI-Generated Photo | G-t-R | 70.2 | 69.4 | 63.6 | 67.5 | 69.7 / 71.4 |
| DREAMLLM | G-t-R | 12.6 | 18.4 | 35.9 | 65.5 | 52.3 / 42.8 | |
| Think with Video | Sora 2 | V-o-T | 67.0* | 75.7* | 67.6★ | 50.5★ | 60.0★ / 70.0★ |
| Think with Comic | TwC (Ours) - Path I | direct | 90.0 | 100.0 | 75.0 | 92.8 | 70.0 / 80.5 |
| TwC (Ours) - Path II | G-t-R | 92.3 | 95.4 | 85.8 | 99.4 | 88.3 / 82.2 |
Different comic styles act as "Visual System Prompts" for different task types:
| Style (Visual Prompt) | MathVista | GSM8K | Avg. Δ |
|---|---|---|---|
| Documentary (Base) | 60.0 | 68.0 | — |
| Slice-of-Life | 80.0 | 86.3 | +19.1 |
| 🕵️ Detective Style | 85.0 | 100.0 | +28.5 |
Detective-style significantly outperforms the documentary baseline with +44.5% relative improvement. This confirms that role-playing narrative style is not merely visual decoration but a potent Visual System Prompt.
The performance-cost curve across different panel counts N. Accuracy enters a plateau at N ∈ [4, 6]. On the MATH500 dataset, token cost ranges between 1100 and 1300. The shaded green region indicates the Pareto optimal range.
Frequency distribution of generated panels across tasks with varying difficulty levels. The shift to the right indicates the model's adaptive allocation of reasoning steps for complex tasks.
Model accuracy under two controlled manipulations of comic panel sequences: Complete Shuffle (blue), which disrupts temporal order, and Intermediate Deletion (orange), which removes intermediate panels while preserving relative order. Accuracy consistently decreases as perturbation intensity increases, with deletion causing a larger drop than shuffling.
Ablation results on textual anchoring. Embedded text (bubbles, narration) provides precise semantic cues that significantly improve accuracy across all benchmarks.
We define the visual signal generation cost function C(·):
Comparing the image generation cost models. While video generation cost (Cvideo) scales linearly with task duration due to temporal redundancy, TwC maintains a low, constant cost (Ccomic) regardless of the event's temporal length. The shaded area represents the economic advantage of our approach. Break-even point at t ≈ 1.34s.
Why Comics Are a Privileged Visual Reasoning Medium ?
We characterize an intermediate representation z by its information-efficiency for task solving:
where I(·;·|·) is conditional mutual information and C(z) is the media generation cost.
If the answer a depends on multi-step temporal relations in latent trajectory s1:T, then any single snapshot x = h(st) may discard relevant states:
Comics represent a structured summary zcomic = (c1:K, τ) with K panels and embedded text τ. By chain rule:
The second term captures the additional semantic anchoring channel from embedded text.
For a video v = (x1, ..., xT) with T frames:
Due to temporal redundancy, I(a; v | q) grows sublinearly with T, while video cost grows linearly.
Comics select K ≪ T key states to maximize task-relevant information:
This leads to higher η(zcomic) than η(v) at the same budget.
This experiment examines whether comics, compared to non-comic visual styles, more naturally and stably support multi-panel generation.
| Metric | Dataset | Comic | Non-Comic | Improvement |
|---|---|---|---|---|
| Layout Success Rate (%) (Panel Consistency) |
MATH-500 | 95.0 | 70.0 | +25.0 |
| MathVista | 90.0 | 65.0 | +25.0 | |
| Reasoning Accuracy (%) | MATH-500 | 75.0 | 60.0 | +15.0 |
| MathVista | 70.0 | 55.0 | +15.0 | |
Table A.1. Comparison of structural stability and reasoning accuracy between Comic and Non-Comic prompts. Comic prompts consistently induce structurally complete multi-panel layouts, while Non-Comic instructions frequently suffer from layout collapse.
This experiment compares Global Comic generation (complete multi-panel comic in a single pass) and Incremental image chaining (panels generated sequentially conditioned on previous outputs).
| Benchmark | Method | ACC (%) ↑ | Logic ↑ | State ↑ | Quality ↑ |
|---|---|---|---|---|---|
| MATH-500 | Incremental | 80.0 | 4.17 | 3.72 | 3.58 |
| Global (Ours) | 95.0 | 4.86 | 4.67 | 4.61 | |
| MathVista | Incremental | 50.0 | 3.50 | 3.50 | 3.40 |
| Global (Ours) | 85.0 | 4.47 | 4.45 | 4.58 | |
| Average | Incremental | 65.0 | 3.83 | 3.61 | 3.49 |
| Global (Ours) | 90.0 | 4.67 | 4.56 | 4.59 | |
Table A.2. Human evaluation results comparing Global and Incremental generation. We evaluate Accuracy (ACC) and three structural metrics (1-5 scale): Logic (reasoning flow), State (consistency between panels), and Quality (visual-textual fidelity). Global generation shows significant superiority in both objective performance and structural coherence.
Figure A.1. Qualitative comparison between (a) Global Comic (Ours) and (b) Incremental Non-Comic generation for a mathematical reasoning task (finding divisors of 196). Global generation maintains a consistent character (FactoBot) and smooth logical flow, whereas the incremental baseline exhibits static scenes and lacks narrative coherence.
Global generation yields significantly stronger cross-panel coherence with more stable entity representations and smoother reasoning progression, whereas incremental generation suffers from error accumulation. This suggests that treating comics as a holistic structured representation is crucial for preserving multi-step reasoning quality.
Example comic outputs from different tasks











@article{chen2026thinkingwithcomics,
title = {Thinking with Comics: Enhancing Multimodal Reasoning through Structured Visual Storytelling},
author = {Chen, Andong and Zhu, Wenxin and Ding, Qiuyu and Song, Yuchen and Yang, Muyun and Zhao, Tiejun},
journal = {arXiv preprint arXiv:2602.02453},
year = {2026}
}